 STECHOQ TRAINING CENTER
STECHOQ TRAINING CENTER
Day 1 - Pengenalan Data & Research Trends

Kecerdasan Buatan (AI) adalah bidang ilmu komputer yang dikhususkan untuk memecahkan masalah kognitif yang umumnya terkait dengan kecerdasan manusia, seperti pembelajaran, pemecahan masalah, dan pengenalan pola. Tujuan AI adalah untuk memberikan kemampuan untuk mengolah input dan menjelaskan output pada perangkat lunak. Pengertian dataset adalah sebuah kumpulan data yang berasal dari informasi-informasi pada masa lalu dan siap untuk dikelola menjadi sebuah informasi baru.
Kumpulan data yang ada di dataset bisa di-load dari sumber data apa pun yang valid, seperti SQL Server database, Microsoft Access database, ataupun dari XML file. Dataset tetap ada di memori dan data di dalamnya bisa dimanipulasi dan di-update tanpa bergantung pada database asalnya. Jika diperlukan, dataset bisa bertindak sebagai template untuk memperbarui database pusat. Dataset berisi koleksi dari nol atau lebih DataTable Object, di mana masing-masing merupakan representasi tabel di memori. Dataset terdiri dari dua jenis, antara lain:
- Private Dataset
Private dataset adalah dataset yang dapat diambil dari sebuah organisasi yang akan dilakukan sebagai objek penelitian, seperti data bank, rumah sakit, sekolah, universitas, perusahaan, dan lain sebagainya - Public Dataset
Public dataset adalah dataset yang bisa diambil dari repository publik yang disepakati oleh pakar peneliti data mining.
Dataset bertujuan untuk menguji suatu metode penelitian yang dikembangkan oleh para pakar peneliti dengan public dataset maupun private dataset. Saat ini, dataset yang banyak digunakan untuk penelitian data mining adalah menguji metode yang dikembangkan oleh pakar peneliti dengan public dataset, sehingga penelitian dapat bersifat comparable (dapat dibandingkan), repeatable (dapat diulang), dan verifiable (dapat diverifikasi).
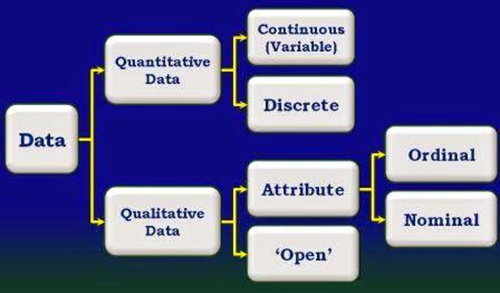
Atribut adalah bagian data, yang mewakili karakteristik atau feature dari objek data. Atribut, dimensi, feature, dan variabel sering digunakan secara bergantian dalam literatur. Istilah dimensi ini umumnya digunakan dalam literatur data warehouse. Dalam literatur Machine learning cenderung menggunakan istilah feature, sementara statistik lebih menggunakan istilah variabel. Jenis atribut ditentukan oleh himpunan nilai yang mungkin muncul, yaitu nominal, biner, ordinal, atau numerik. Dalam bagian berikut, kita bahas tentang masing-masing jenis.
- Atribut Nominal
Nominal berarti "yang
berkaitan dengan nama-nama." Nilai-nilai atribut nominal adalah simbol
atau nama-nama dari suatu benda. Setiap nilai merupakan semacam kategori, kode,
atau status dan sebagainya sehingga atribut nominal juga disebut sebagai
kategorikal. Nilai-nilai di dalamnya tidak memiliki urutan. Dalam ilmu
komputer, nilai-nilai tersebut disebut juga dengan enumerasi. - Atribut Biner
Sebuah atribut biner adalah
atribut nominal yang hanya berisi dua jenis nilai saja: 0 atau 1, di mana 0
biasanya berarti bahwa atribut tidak ada, dan 1 berarti bahwa itu ada. Contoh
lain adalah atribut yang nilainya hanya berisi 'ya' dan 'tidak'. Atribut biner
disebut sebagai Boolean jika kedua status berkaitan dengan true dan false. - Atribut Ordinal
Sebuah atribut ordinal adalah
atribut dengan nilai-nilai yang memiliki urutan atau peringkat, tapi besaran
nilai-nilai yang berurutan tidak diketahui. - Atribut Numerik
Atribut numerik adalah
kuantitatif; artinya, nilai atribut itu bisa diukur, disajikan dalam bentuk
integer atau desimal. Atribut numerik bisa berupa interval-scaled
(berskala interval) atau ratio-scaled (berskala rasio).
Nominal berarti "yang berkaitan dengan nama-nama." Nilai-nilai atribut nominal adalah simbol atau nama-nama dari suatu benda. Setiap nilai merupakan semacam kategori, kode, atau status dan sebagainya sehingga atribut nominal juga disebut sebagai kategorikal. Nilai-nilai di dalamnya tidak memiliki urutan. Dalam ilmu komputer, nilai-nilai tersebut disebut juga dengan enumerasi.
Sebuah atribut biner adalah atribut nominal yang hanya berisi dua jenis nilai saja: 0 atau 1, di mana 0 biasanya berarti bahwa atribut tidak ada, dan 1 berarti bahwa itu ada. Contoh lain adalah atribut yang nilainya hanya berisi 'ya' dan 'tidak'. Atribut biner disebut sebagai Boolean jika kedua status berkaitan dengan true dan false.
Sebuah atribut ordinal adalah atribut dengan nilai-nilai yang memiliki urutan atau peringkat, tapi besaran nilai-nilai yang berurutan tidak diketahui.
Atribut numerik adalah kuantitatif; artinya, nilai atribut itu bisa diukur, disajikan dalam bentuk integer atau desimal. Atribut numerik bisa berupa interval-scaled (berskala interval) atau ratio-scaled (berskala rasio).
Discrete VS Continuous
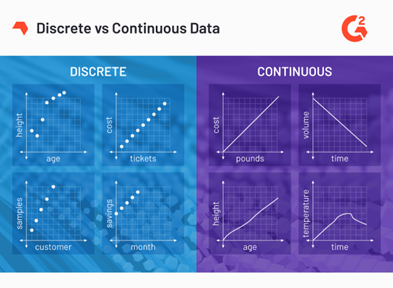
Diskrit
Kalau kita mendapatkan hasil pengukuran dengan cara enumerasi atau membilang satu per satu, misalkan satu, dua,tiga,..dst,.dst. Contoh: berapa jumlah siswa di dalam kelas X? Jawaban didapatkan dengan membilang/enumerasi dengan menghitung siswa satu per satu: satu, dua,tiga,...,empat puluh. Misalkan hasilnya adalah 40 siswa.Kontinyu
Kalau kita mendapatkan hasil pengukuran dengan cara mengukur, misalnya berapa jarak ujung dinding A ke ujung dinding B? Hasil yang didapatkan adalah dengan cara mengukur misalnya menggunakan alat pengukur dan hasil yang didapatkan, misalnya, adalah 10,5 meter.A. Data-Centric AI
Data-Centric AI adalah
pendekatan teknologi yang muncul di AI. Evolusi pendekatan baru biasanya
dimulai dengan beberapa ahli yang melakukan teknik secara intuitif. Ketika para
ahli ini mendiskusikan dan mempublikasikan ide-ide mereka, prinsip-prinsip ini
menjadi lebih luas dan akhirnya, alat dikembangkan untuk membuat aplikasi
mereka lebih sistematis dan tersedia untuk semua orang.
B. BigQuery Explainable AI (XAI)
BigQuery Explainable AI (XAI) adalah seperangkat alat dan kerangka kerja untuk membantu memahami dan menafsirkan prediksi yang dibuat oleh model pembelajaran mesin, yang terintegrasi secara bawaan dengan sejumlah produk dan layanan Google. Dapat men-debug dan meningkatkan kinerja model, dan membantu orang lain memahami perilaku model. Juga dapat membuat atribusi fitur untuk prediksi model di Tabel AutoML, BigQuery ML, dan Vertex AI, serta menyelidiki perilaku model secara visual menggunakan alat.
C. Automated ML

Pembelajaran mesin otomatis, juga disebut sebagai ML atau AutoML otomatis, adalah proses mengotomatiskan tugas pengembangan model pembelajaran mesin yang memakan waktu dan berulang. Pembelajaran mesin otomatis memungkinkan ilmuwan data, analis, dan pengembang untuk membangun model ML dengan skala, efisiensi, dan produktivitas tinggi sambil mempertahankan kualitas model.
Latihan
Carilah beberapa dataset yang ada di internet, salah satu sumber yang sering digunakan para data saintis adalah kaggle.com namun dataset dapat dicari melalui sumber lainnya. Lakukanlah analisis dataset yang Anda kumpulkan, seperti melakukan analisis pada tipe data yang dimilikinya.
Referensi Baca
- Understanding Data Attribute Types | Qualitative and Quantitative - GeeksforGeeks
- Artificial Intelligence/Kecerdasan Buatan – Apa itu dan mengapa hal itu penting | SAS
- What is automated machine learning (AutoML)? (techtarget.com)
- Trend Data Science 2022 Membuat Hidup Lebih Mudah - Algoritma
- Memahami Data - Repositori Kuliah Data Mining (mulaab.github.io)
- Jenis-jenis Data Analytics – MMSI BINUS University
- Data Centric AI
- Tips for a Data-Centric AI Approach - Landing AI
- Explainable AI | IBM
- Explainable AI | Google Cloud
- AutoML | AutoML
Last modified: Thursday, 16 February 2023, 11:59 PM
