 STECHOQ TRAINING CENTER
STECHOQ TRAINING CENTER
Day 2 - Data Exploration & Preprocessing
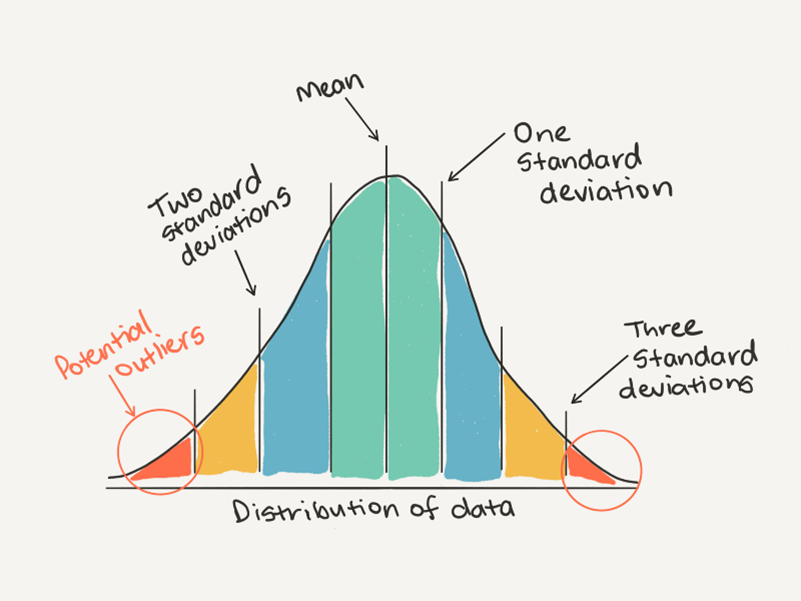
Data Exploration
Exploratory Data Analysis adalah suatu proses uji investigasi awal yang bertujuan untuk mengidentifikasi pola, menemukan anomali, menguji hipotesis dan memeriksa asumsi. Dengan melakukan EDA, pengguna akan sangat terbantu dalam mendeteksi kesalahan dari awal, dapat mengidentifikasi outlier, mengetahui hubungan antar data serta dapat menggali faktor-faktor penting dari data. Proses EDA ini sangat bermanfaat dalam proses analisis statistik.
1. Data Cleaning
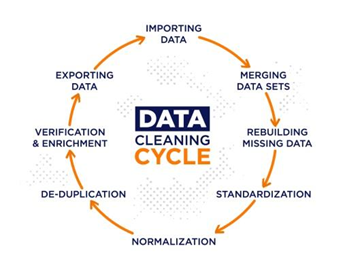
Data
yang baru saja dikumpulkan kemungkinan besar memiliki banyak bagian yang tidak
relevan bahkan ada bagian yang hilang. Oleh karena itu perlu adanya proses
pembersihan data atau biasa dikenal dengan data cleaning. Hal yang bisa diatasi
menggunakan data cleaning adalah penanganan missing value dan noise. Missing
value merupakan kondisi dimana adanya data yang hilang atau tidak lengkap di
dalam database. Cara untuk mengatasi missing value adalah dengan mengabaikan
tupel dan mengisi missing value tersebut. Pengabaian tuple cocok digunakan jika
dataset yang digunakan cukup besar dan ada beberapa missing value dalam sebuah
tupel. Pengisian missing value dapat dilakukan dengan beberapa cara, seperti
mengisi manual missing value tersebut dengan mean atau nilai lain sesuai dengan
jenis data. Noise merupakan data yang tidak berguna yang tidak dapat
diinterpretasikan oleh tools. Noise ini muncul karena pengumpulan data yang
salah, entri data yang kurang tepat, dan lain sebagainya.
2. Data Transformation
Data transformation digunakan untuk mengubah data dalam bentuk yang sesuai dalam proses data mining. Beberapa teknik untuk data transformation adalah normalization, pemilihan attribute, dan discretization. Normalization dilakukan untuk menskalakan nilai data dalam rentang nilai tertentu, misalnya -1 sampai 1 atau 0 sampai 1. Teknik kedua adalah pemilihan atribut. Pemilihan atribute merupakan proses pemilihan atribut yang diberikan untuk proses data mining. Terakhir adalah teknik discretization. Teknik ini dilakukan untuk mengganti raw value pada atribut numerik dengan nilai interval.
3. Data Reduction
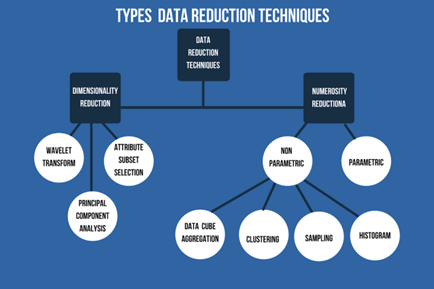
Analisis data yang menggunakan dataset dalam ukuran besar akan sangat sulit dilakukan, oleh karena itu, perlu adanya teknik data reduction dengan tujuan untuk meningkatkan efisiensi penyimpanan serta mengurangi biaya penyimpanan dan analisis data. Data reduction dibagi menjadi beberapa teknik, yaitu Data Cube Aggregation, Attribute Subset Selection, Numerosity Reduction, dan Dimensionality Reduction. Teknik-teknik ini memiliki fungsi dan tujuan masing-masing
Latihan
Lakukan pemrosesan terhadap salah satu dataset yang kalian dapatkan pada Day 1. Contoh pemrosesan data yang dilakukan dapat dilihat pada notebook berikut
https://colab.research.google.com/drive/1dW3WaAmrNAC-jGAINcRGUFP4vdvH70nV?usp=sharing
Referensi
- Langkah Awal dalam Pemrosesan Data: Data Preprocessing dalam... (dqlab.id)
- Proses Analisis Data Lebih Mudah dengan Data Preprocessing - Algoritma
- Data Exploration & Image Pre-Processing.ipynb - Colaboratory (google.com)
- Exploratory Data Analysis : Pahami Lebih Dalam untuk Siap Ha... (dqlab.id)
- Memahami Data Dengan Exploratory Data Analysis | by Andreas Chandra | Data Folks Indonesia | Medium
- Transformasi Data dalam Tahapan Data Mining (chandraallim.blogspot.com)
- Data Reduction: A Simple And Concise Guide (2021) (jigsawacademy.com)
Last modified: Friday, 17 February 2023, 12:04 AM
