 STECHOQ TRAINING CENTER
STECHOQ TRAINING CENTER
11. Tensorflow - Text
Tensorflow - Text
Pendahuluan
Halo Stupenss!, setelah sebelumnya kita sudah membahas tensorflow dan NLP selanjutnya mari kita belajar untuk melakukan pemrosesan NLP dengan menggunakan Tensorflow, kita akan menggunakan tensorflow untuk melakukan segmentasi teks, jadi mari kita belajar bersama.
Tensorflow - Teks
Kita tahu bahwa tensorflow merupakan salah satu framework untuk machine learning yang sangat powerfull, jadi kita akan menggunakan ini untuk membantu kita dalam mengolah suatu teks, kita akan menerapkan konsep dari NLP yaitu pada segmentasi teks, serta menggunakan tensorflow untuk membangun model machine learningnya. Tahap yang akan dilakukan adalah :
Persiapan Data
import pandas as pd
df = pd.read_csv("wine-reviews.csv", usecols = ['country', 'description', 'points', 'price', 'variety', 'winery'])
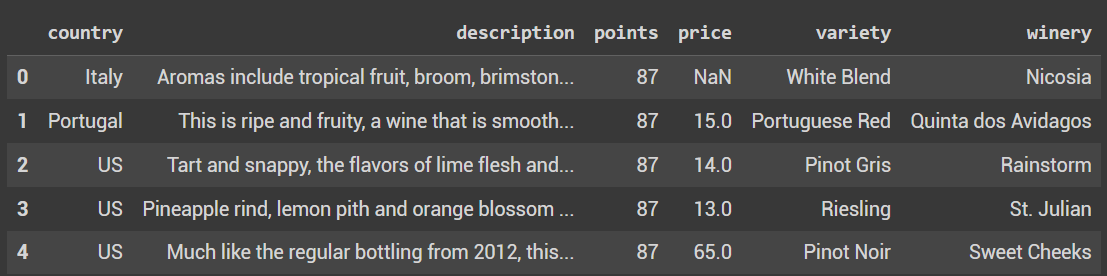
df.head()
kita akan melakukan import data dengan menggunakan library pandas dataset yang akan kita gunakan adalah pandas, pada dataset yang akan kita gunakan hanyalah kolom country, description, points, price, variety, dan winery.
Processing Data
# Menghilangkan data kosong untuk kolom description dan points
df = df.dropna(subset=["description", "points"])
baris kode diatas merupakan salah satu method dari pandas juga yaitu dropana yang berfungsi untuk menghapus data yang null atau NaN, di sini target data yang akan diperiksa adalah kolom tabel dan points.
# Menampilkan data berdasarkan jumlah poin
plt.hist(df.points, bins=20)
plt.title("Points histogram")
plt.ylabel("N")
plt.xlabel("Points")
plt.show()
pada data diatas kita akan melihat histogram data dari jumlah poin sehingga kita dapat mudah mencari informasi yang dibutuhkan
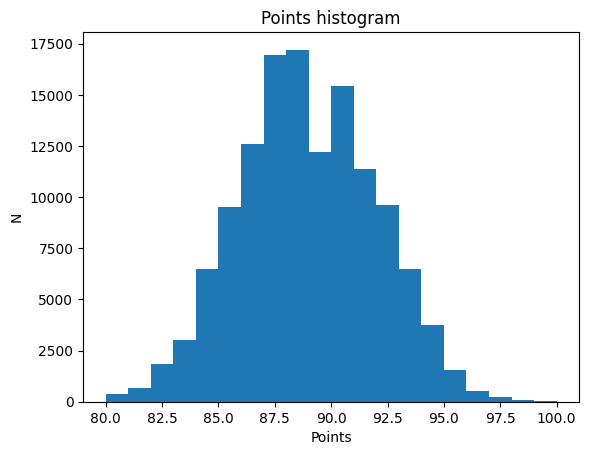
dari histogram diatas kita dapat melihat persebaran dari points, dengan ini kita dapat mengelompokkan menjadi 2 yaitu nilai lebih atau sama dengan 90 dan di bawah 90, sehingga kita dapat mengelompokkan sebagai berikut
# mengelompokkan data berdasarkan jumlah poin >=90 dan diberikan label 0 untuk poin <90 dan 1 untuk poin >= 90
df["label"] = (df.points >= 90).astype(int)
df = df[["description", "label"]]
akan menambahkan kolom baru yaitu label untuk mengidentifikasi dari kelompok points tadi, serta kita akan menggunakan kolom description karena data teks description yang akan kita olah.

Spit Data
# rasio untuk variabel train : validation : test adalah 80 : 10 : 10
train, val, test = np.split(df.sample(frac=1), [int(0.8*len(df)), int(0.9*len(df))])
setelah kita mendapatkan dataset kita akan membaginya kedalam 3 variabel yaitu data train, data validasi, dan data test, dengan rasio 80 : 10 : 10.
print('Jumlah data :',len(df))
print('Data train :', len(train))
print('Data validation :', len(val))
print('Data test :', len(test))
kita akan melihat pembagian jumlah datanya dengan menampilkan panjang dari data
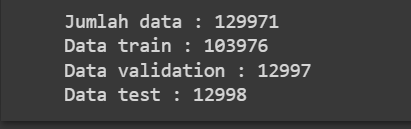
Kita bisa melihat jumlah datanya begitu besar ini dapat memberatkan memori pada saat pemrosesan oleh karena itu kita harus mengambil sampel dari setiap dataset dengan menggunakan metode df_to_dataset.
# membungkus data untuk diambil sampelnya aja karena datanya sangat besar
def df_to_dataset(dataframe, shuffle=True, batch_size=1024):
df = dataframe.copy()
labels = df.pop('label')
df = df["description"]
ds = tf.data.Dataset.from_tensor_slices((df, labels))
if shuffle:
ds = ds.shuffle(buffer_size=len(dataframe))
ds = ds.batch(batch_size)
ds = ds.prefetch(tf.data.AUTOTUNE)
return ds
Kita akan menjalankan fungsinya dan dimasukkan hasilnya ke dalam variabel baru, variabel baru ini yang akan kita train kedalam model.
train_data = df_to_dataset(train)
val_data = df_to_dataset(val)
test_data = df_to_dataset(test)
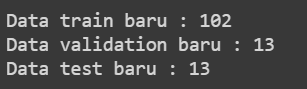
print(len(train_data), 'train examples')
print(len(val_data), 'validation examples')
print(len(test_data), 'test examples')
kita akan mencoba menampilkan hasil dari sampel diatas yang sudah dibuat untuk melihat jumlah data yang sudah dibuat sampelnya
Embedding
Embedding merupakan metode untuk mengubah bentuk string menjadi angka, karena komputer lebih membaca angka dibandingkan dengan string, jadi kalimat kalimat pada teks akan diubah menjadi bentuk kode.
embedding = "https://tfhub.dev/google/nnlm-en-dim50/2"
hub_layer = hub.KerasLayer(embedding, dtype=tf.string, trainable=True)
Untuk melakukan embedding kita menggunakan repository yang disediakan oleh tensorflow yaitu tensorhub, kita akan menggunakan file embed nnlm-en-dim50 yang merupakan kumpulan teks berbasis token dilatih dalam corpus Google News 7B bahasa Inggris.
Creating Model
model = tf.keras.Sequential()
model.add(hub_layer)
model.add(tf.keras.layers.Dense(16, activation='relu'))
model.add(tf.keras.layers.Dropout(0.4))
model.add(tf.keras.layers.Dense(16, activation='relu'))
model.add(tf.keras.layers.Dropout(0.4))
model.add(tf.keras.layers.Dense(1, activation='sigmoid'))
Kita sampai pada tahap pembuatan model, pada model ini kita akan menerapkan sequential model dari library keras, kemudian kita akan tambahkan layer layer pada model kita disini terdapat 6 layer yaitu :
Pada layer pertama terdapat hub_layer yang berfungsi untuk embedding, jadi data input akan melalui proses embedding untuk mengubah bentuk string menjadi bentuk kode,
Setelah itu akan diproses pada layer berikutnya yang memiliki 16 nodes, dan menggunakan activation ReLu
Lalu data akan melalui proses drop out, pada layer ini bobot dari unit akan dikalikan dengan probabilitas pada dropout, ini berfungsi untuk mencegah terjadinya overfitting pada model.
Pada layer terakhir menggunakan 1 nodes dan activation layer sigmoid.
model.compile(optimizer=tf.keras.optimizers.Adam(learning_rate=0.001),
loss=tf.keras.losses.BinaryCrossentropy(),
metrics=['accuracy'])
Setelah model selesai dibuat kemudian model akan di compile dengan konfigurasi optimizer menggunakan Adam dengan learning rate 0.001, setelah itu loss menggunakan BinaryCrossentropy() dan metrics akan mengukur akurasi.
Training Model
Setelah itu kita akan melakukan training pada model pada model yang sudah kita buat, yaitu sebagai berikut
train = model.fit(train_data, epochs=5, validation_data=val_data)
Pada proses train ini kita menggunakan data train dan jumlah epochs 5 dan melakukan validasi data.
Testing Model
model.evaluate(test_data)
Setelah melakukan training model kita akan melakukan melakukan testing pada model kita dengan data test, untuk melihat hasil accuracy dari modelnya.
Referensi
https://medium.com/analytics-vidhya/understanding-embedding-layer-in-keras-bbe3ff1327ce
https://towardsdatascience.com/mastering-word-embeddings-in-10-minutes-with-tensorflow-41e25da6aa54
https://djajafer.medium.com/multi-class-text-classification-with-keras-and-lstm-4c5525bef592
Last modified: Thursday, 2 November 2023, 8:22 AM
